From RankNet to LambdaRank to LambdaMART: An Overview[^1]を基にRankNetの説明とPytorchによる実装をしていきたいと思います.
RankNetは, 一言で言うとPairwiseの手法を用いたランク学習モデルです.
ランク学習とは?
ランク学習は, 教師あり機械学習を用いてランキング結果を最適化する手法.
従来は, TF-IDFやBM25といったクエリと文書間の関連度を基にランキングしたり, PageRankのように文書自体の重要度を基にランキングしていました.
最近では, より関連度の高い文書を上位にランキングするために上の二つの要素を含む様々な特徴量を基にランキングを行なっています. ちなみに, ランク学習でよく用いられるデータセットのMQ2007,MQ2008では文書の特徴量が46個あり, MSLR-WEBでは136個もあります.
したがって, この多くの特徴量の中でどの特徴量にどれだけ重みを置くかが重要になってきます. (PageRankが高ければクエリと適合している文書と言えるのか?..など) そこで, 機械学習を用いてランキングの最適化を行なったのがランク学習です.
みなさんがよく使う検索エンジンではランク学習を用いて検索結果を最適化していると言われていて, 以下の図がランク学習の様子を表した図です.
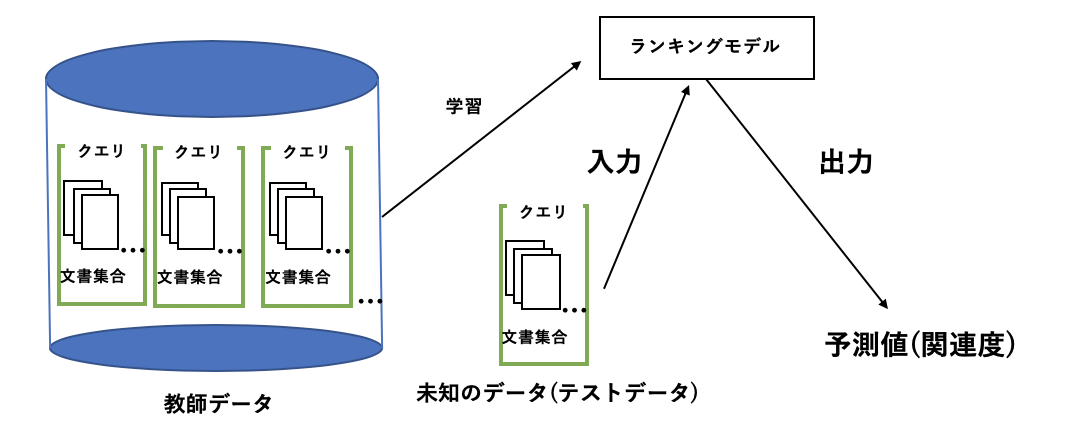
このランク学習には, 学習の方法によって, Pointwise手法, Pairwise手法, Listwise手法があります.
- Pointwise : 単一のクエリと文書のペアに対して損失関数を設定し学習を行う
- Pairwise : クエリに対する文書のペアに対して損失関数を設定し学習を行う
- Listwise : クエリに対する全ての文書のリストに対して損失関数を設定し学習を行う
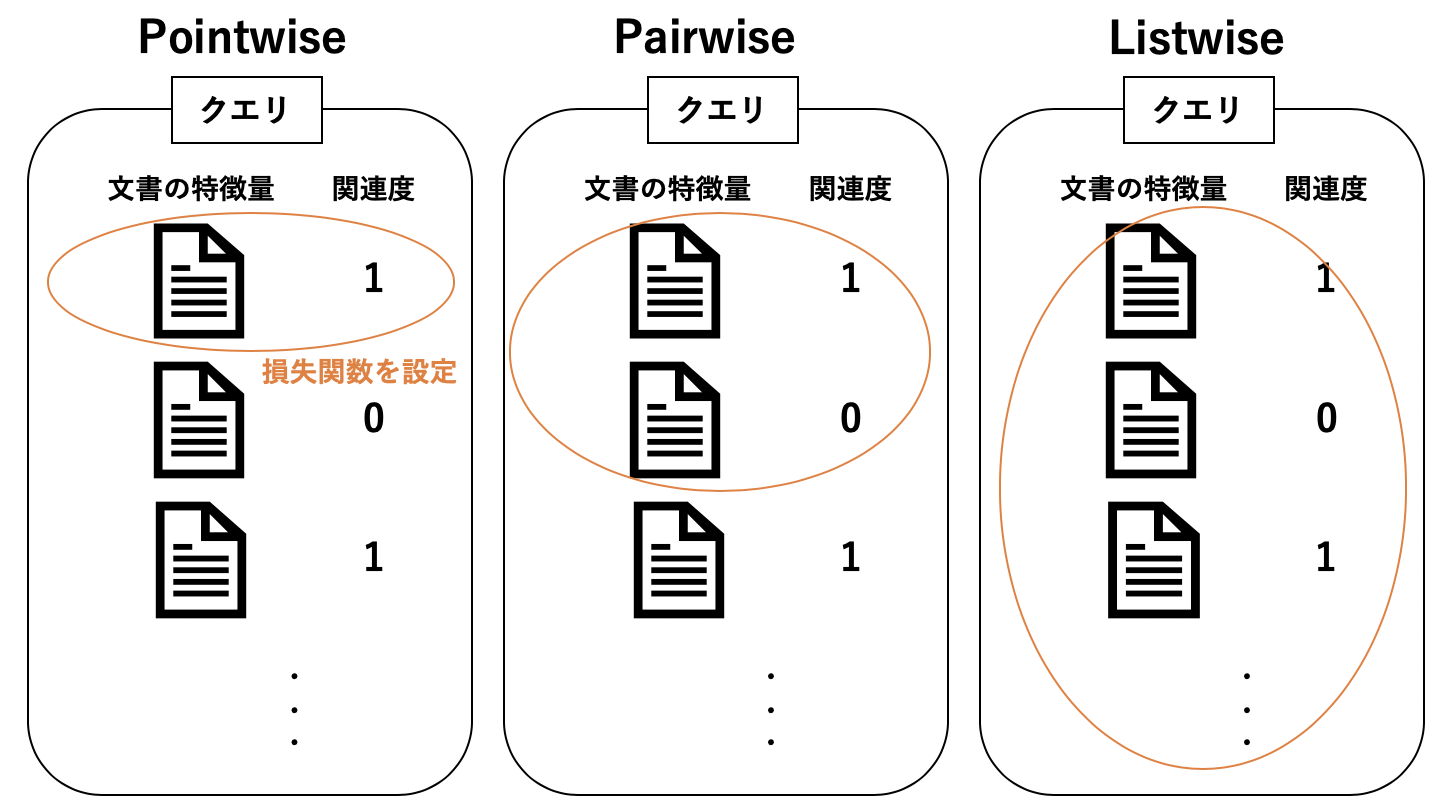
今回紹介するRankNetはPairwise手法のランキングモデルです.
RankNetの概要
あるクエリにおける2つの異なる文書$U_i$と$U_j$において, 文書$U_i$の方が$U_j$よりも関連度が高い$(Ui⊳Uj)$と仮定します.
文書$U_i$と$U_j$をモデルへ入力として与えた時のスコア(関連度)をそれぞれ$s_i=f(x_i), s_j=f(x_j)$とすると($x$は文書の特徴ベクトル),
この2つのスコアを用いて , $U_i⊳U_j$となる確率$P_{ij}$を以下のように定義できます.
$$ P_{ij} ≡ $U_i⊳U_j$ ≡ \frac{1}{1 + e^{- \sigma(s_i - s_j)}}$$
ここで, $\sigma$はシグモイド関数の形を決めるスカラー値.
この$P_{ij}$が真の$\bar{P}_{ij}$に近づくようにランキングモデルを学習させていきます.
RankNetでは学習において損失関数として交差エントロピー誤差を用いてます.
$$C=-\bar{P}{ij}\log P{ij} - (1 -\bar{P}{ij})\log (1-P{ij})$$
ここで, 教師データでは事前にそれぞれの文書の関連度が分かっているので, 文書$U_i$が文書$U_j$より関連度が高い場合は1を, 逆の場合は-1, 同じ場合は0を与える教師ラベル$S_{ij}$を以下のように定義すると,
$$S_{ij}=\begin{cases}1 & (U_i \rhd U_j) \ -1 & (U_j \rhd U_i) \ 0 & (\mathrm{otherwise}) \end{cases}$$
真の確率は, $\bar{P}{ij}=\frac{1}{2}(1+S{ij})$となり, この式を上の損失関数の式に代入すると, 以下のような損失関数が得られます.
$$C=\frac{1}{2}(1-S_{ij})\sigma(s_i-s_j)+\log (1+e^{-\sigma(s_i-s_j)})$$
そして, 学習する際は, SGDを用いて以下のように重みを更新していきます.
$$ w_k -> w_k - \eta \frac{\partial C}{\partial w_k}$$
PytorchによるRankNetの実装
今回はMQ2007というデータセットを用いてRankNetの実装を行いました.
MQ2007では一つのクエリに対して平均で約40個の文書がペアとなっています.(クエリの数は約1020個くらい)40個の文書を重複無しでペアにする組み合わせの数は780通りあり, 一つずつ計算してくと時間がかかるので, バッチ処理を行いました.
具体的には, 40個の文書をそれぞれモデルに入力し得られた予測値$s_i$, $s_j$から$s_i - s_j$のペアを作成し, 以下のように重複を取り除きました.
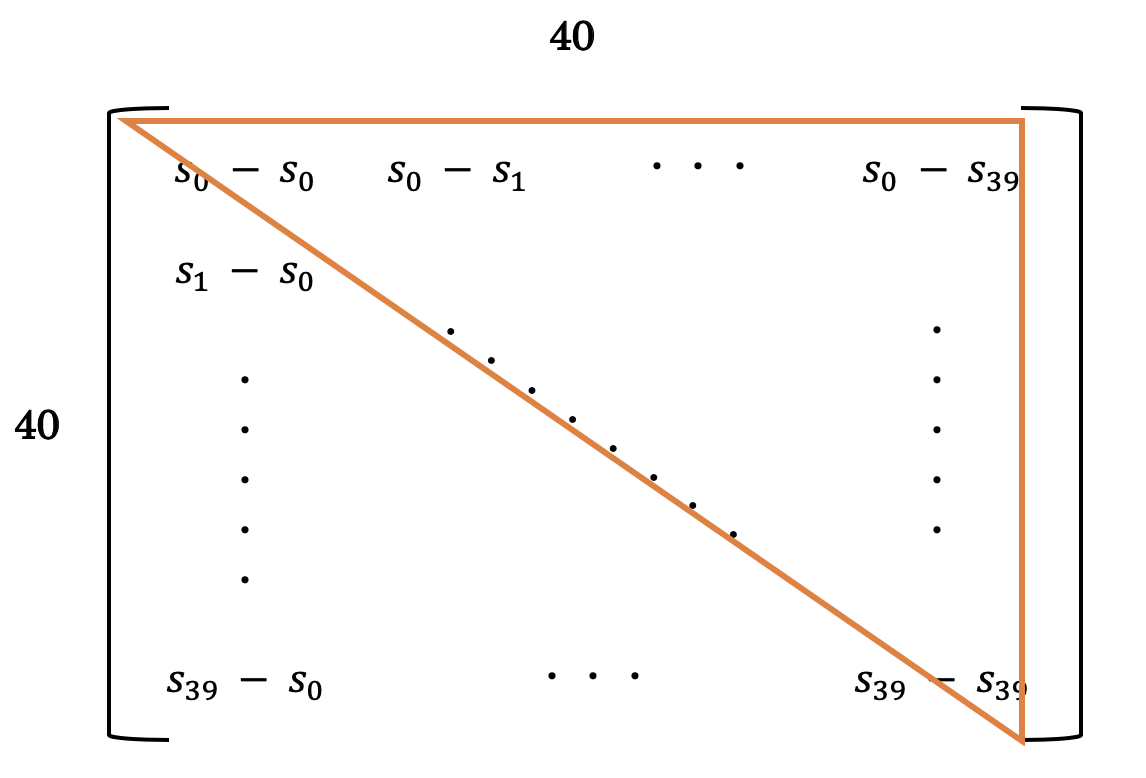
モデルは以下のような構造に設定しました.
そして, 損失は以下のように計算しています.
とりあえず50epoch回してみたところ結果は以下のようになりました.
- TrainのNDCG@10(Fold1)
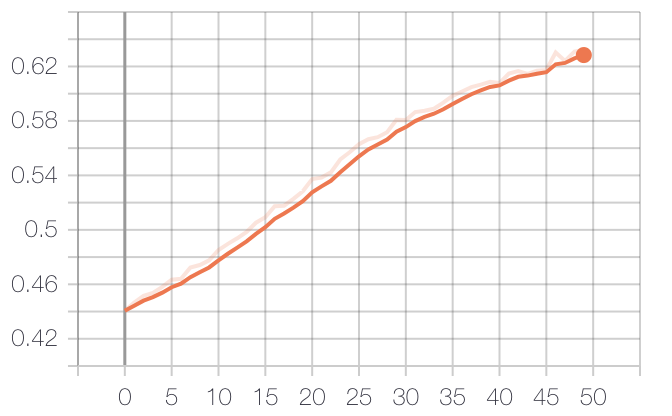
- ValidationのNDCG@10(Fold1)
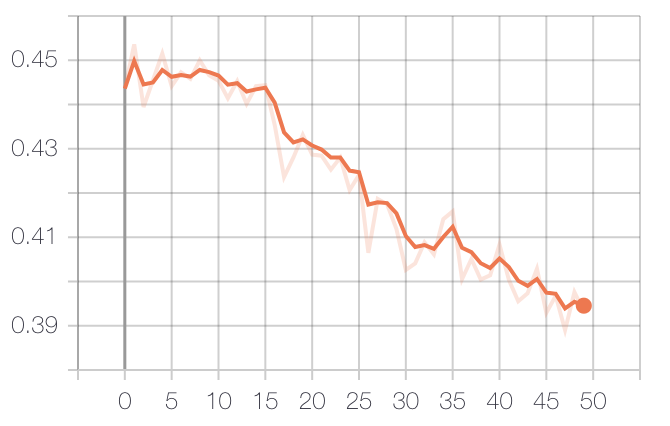
そして, テストデータにおけるNDCGは以下のようになっています.
NDCGの値はこんなもんなのでしょうか?
どこか間違えてるような気が…
指摘やコメントお待ちしています!